Using Emoji in Web Apps
By Cal Henderson, October 21st 2009.
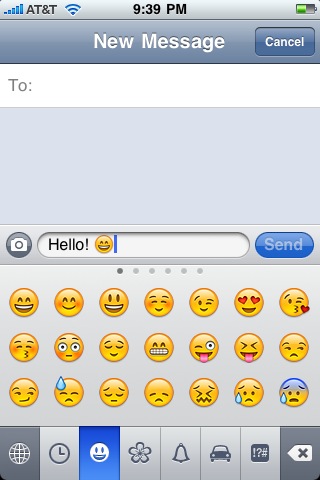
If you haven't been locked in a small box for the past year, then you'll be familiar with the screenshot on the left - the Emoji keyboard on the iPhone. If you haven't unlocked yours yet, just go into the app store and search for 'emoji' to find an app.
Emoji is the Japanese term for small emoticon pictures. The word 'e moji' literally means 'picture letter'. They've seen widespread adoption in the Japanese mobile market, with multiple providers adding the ability to send these pictograms as part of text messages, emails and on web pages.
This is achieved via the Unicode Private Use character space, a large set of code points where vendors can define their own meanings. This is all well and good, but of course nobody agrees on what code points should mean which pictures.
The players in the space for the most part were NTT DoCoMo, KDDI/Au and Softbank/Vodafone. More recently, Apple have added emoji support to the iPhone and Google to the Android mobile operating system. While Apple chose to use the Softbank/Vodafone mappings, all of the others are distinct, creating four different standards.
Using Emoji
Exchanging little pictures in SMS is pretty fun for while, but why should that fun be limited to SMS? If we're building web apps which receive data from mobile devices or display data on them, we should be able to leverage these little critters. We can even create them ourselves as iconography without the cost of creating and serving image files.
But this isn't trivial - different devices use different code points (an iPhone can't display a smiley face entered on an Android phone) and people will be using your web app with a regular desktop browser too. Luckily, there's a reasonable solution to all these problems.
The Unified Set
There's a Unicode proposal from folks at Google and Apple to standardize emoji down to a single set of code points. While these code points haven't yet been formalized, this proposal contains a way to map each of the four different schemes. By using this unified mapping internally within our application, we can convert from any input scheme to any other output scheme.
At input time, we need to know where the data has come from, since some of the different sets overlap - both Softbank's 'frog face' and KDDI's 'small white square' are represented by U+E531. If we convert from the native encoding to the unified encoding for storage, we don't need to store the format. At output time, we can detect which platform we're delivering content to and convert from the unified set to the platform specific set.
Not all of the platform's emoji sets are equal though, so some symbols appear in only one set, or appear multiple times. For instance, KDDI has an emoji called 'large white square' with a code point of U+E548. DoCoMo doesn't have any equivalent at all, while Softbank has U+E21B meaning 'white rounded square' which can be used in its place. The proposal includes one-way mappings for some missing characters and replacement text for others - while all emoji are not supported by all platforms, there is a recommended replacement for them.
Back to the desktop
This is all well and good, but what should we do if someone enters emoji on their device which we want to display to non-mobile users? The unified set are Unicode code points which are defined by some fonts, but the pictures will be monotone and are missing from most common web fonts.
With a smart bit of output-processing, we can replace characters from the unified set with HTML to show inline images. At display time, our code can search for instances of the UTF-8 byte sequence 0xE2 0x98 0xBA (known to friends as U+263A, the smiley face) and replace them with <img src="/emoji/smiley_face.gif" class="emoji" />, or whatever HTML we wish to use.
Speed Concerns
The unified set is pretty big, covering 772 characters. Performing a search and replace at display time is going to take a couple of milliseconds, so for heavily trafficked applications, we might need to start worrying about performance. Luckily there are a few tricks.
Assuming most of your content doesn't contain emoji, you can add an extra field to your database rows called contains_emoji. By setting this at insert time, you can only spend time transcoding the emoji at output time if there are actually any in there.
If your application has lots and lots of emoji content, then storing multiple versions of your content with different emoji formats in might make sense. If you know you're primarily serving to DoCoMo users, then store both a unified and a DoCoMo copy. When you need to serve to DoCoMo, use that version, else convert from the unified version.
A library to make it all happen
I've put together a simple PHP library to abstract all of the messiness away. Just include it in your application and start detecting emoji right away. Instructions are included in the readme file.
Post-Script
While I'm a bit of a Unicode nerd, I'm no expert. The above article may contain mistakes or fail to mention very important things. If you spot any glaring mistakes or omissions, drop me an email and teach me: cal [at] iamcal.com
Copyright © 2009 Cal Henderson.
The text of this article is all rights reserved. No part of these publications shall be reproduced, stored in a retrieval system, or transmitted by any means - electronic, mechanical, photocopying, recording or otherwise - without written permission from the publisher, except for the inclusion of brief quotations in a review or academic work.
All source code in this article is licensed under the GPL v3.
48 people have commented


Install the extension and you can now see emoji for twitter or other website.
<a href="https://chrome.google.com/extensions/detail/fbgkphlalcbmifhkabdbodaghlhfcbbd">chrome.google.com/extensions/detail/fbgkphlalcbmifhkabdbodaghlhfcbbd</a>
<a href="https://twitter.com/chrome_emoji">twitter.com/chrome_emoji</a>


I was trying to encode emojis in my sql database using htmlentities() but it wasn't working.
Thank you for this library.



I'm looking forward to finding a way to use this in a web app.
Presuming that the squares that show up on phones when you send iPhone emojis to other models have some code behind them surely it would be possible to write an Android app to recieve/decode iPhone emojis and vice versa using the info from this page?
First: Attack of the Grammarnazi! It's "worthwhile", iPhoned.



There's also a russian jquery plugin out there that attempts to do the same thing, but it's a little quirky and I needed to tinker with it a while before it worked for me.
<a href="http://plugins.jquery.com/project/emoji">plugins.jquery.com/project/emoji</a>


Also if you find emoji on the web or in an email and all you see is boxes; you can cut and paste the emoji characters into <a href="http://iemoji.com">iemoji.com</a> and they will be converted for you.

Is this possible and how? (if i can do so, then i give up on my iphone and enter the droid world, thats the issue)
<a href="https://chrome.google.com/webstore/detail/aepnepljbnakkkhjegpdklnmccdnadjj">chrome.google.com/webstore/detail/aepnepljbnakkkhjegpdklnmccdnadjj</a>


<a href="http://forum.xda-developers.com/showthread.php?t=1093197">forum.xda-developers.com/showthread.php?t=1093197</a>
I thread I did to mess with the fonts to see as much as I can but it is black and white. There are 10s of thousands of people who would like to see emoji through all apps on the Android if possible.
Is this the deal?
<a href="http://obviam.net/index.php/using-bitmap-fonts-in-android/">obviam.net/index.php/using-bitmap-fonts-in-android</a>
Thanks!

From an iPhone App a message is sent to an external PHP script. But curiously:
$_POST["message"] == emoji_softbank_to_unified($_POST["message"])
Hmmm, get really stucked with this.
BTW: I managed to save the Emoji message to a MySQL database only with utf8mb4.



How can one detect the emoji format of an incoming SMS data stream, as one of these formats? :
NTT DoCoMo
KDDI/Au
Apple/Softbank/Vodafone
The library assumes that one knows the incoming format, hence methods such as:
$data = emoji_docomo_to_unified( $data ) ;
Is there a way to do something like this? :
$format = get_emoji_format( $data ) ;
where $format is (for example) one of: ["docomo", "kddi", "google", "apple"]
Thank you Cal, for this great work !

<a href="https://chrome.google.com/webstore/detail/emoji-input/immhpnclomdloikkpcefncmfgjbkojmh/reviews?hl=en-US">chrome.google.com/webstore/detail/emoji-input/immhpnclomdloikkpcefncmfgj...</a>


Get code:
<a href="http://code.iamcal.com/php/emoji/">code.iamcal.com/php/emoji</a> (U+1F48E)
Lookup:
(change U+ to 0x: 0x1F48E, and Lookup)
<a href="http://unicodelookup.com/">unicodelookup.com</a>
copy returned symbol and paste to your text.

<a href="http://stackoverflow.com/questions/2430206/how-can-i-scale-an-image-in-a-css-sprite">stackoverflow.com/questions/2430206/how-can-i-scale-an-image-in-a-css-sp...</a>
For older browsers that don't support that, you get the current behavior.




People
Face
😀 😠😂 😃 😄 😅 😆 😇 😈 👿 😉 😊 â˜ºï¸ ðŸ˜‹ 😌 😠😎 😠😠😑 😒 😓 😔 😕 😖 😗 😘 😙 😚 😛 😜 😠😞 😟 😠😡 😢 😣 😤 😥 😦 😧 😨 😩 😪 😫 😬 😠😮 😯 😰 😱 😲 😳 😴 😵 😶 😷 🙠🙂 😸 😹 😺 😻 😼 😽 😾 😿 🙀 👣 👤 👥 👦 👧 👨 👩 👨â€ðŸ‘©â€ðŸ‘¦ 👨â€ðŸ‘©â€ðŸ‘§ 👪 👨â€ðŸ‘©â€ðŸ‘¦â€ðŸ‘¦ 👨â€ðŸ‘©â€ðŸ‘§â€ðŸ‘§ 👩â€ðŸ‘©â€ðŸ‘¦ 👩â€ðŸ‘©â€ðŸ‘§ 👩â€ðŸ‘©â€ðŸ‘§â€ðŸ‘¦ 👩â€ðŸ‘©â€ðŸ‘¦â€ðŸ‘¦ 👩â€ðŸ‘©â€ðŸ‘§â€ðŸ‘§ 👨â€ðŸ‘¨â€ðŸ‘¦ 👨â€ðŸ‘¨â€ðŸ‘§ 👨â€ðŸ‘¨â€ðŸ‘§â€ðŸ‘¦ 👨â€ðŸ‘¨â€ðŸ‘¦â€ðŸ‘¦ 👨â€ðŸ‘¨â€ðŸ‘§â€ðŸ‘§ 👫 👬 👠👮 👯 👰 👱 👲 👳 👴 👵 👶 👷 👸 💂 👼 🎅 👻 👹 👺 💩 💀 👽 👾 🙇 💠🙅 🙆 🙋 🙎 🙠💆 💇 💑 👩â€â¤ï¸â€ðŸ‘© 👨â€â¤ï¸â€ðŸ‘¨ 💠👩â€â¤ï¸â€ðŸ’‹â€ðŸ‘© 👨â€â¤ï¸â€ðŸ’‹â€ðŸ‘¨ 💅 👂 👀 👃 👄 💋 👅
Hand Gesture
👋 👠👎 â˜ï¸ 👆 👇 👈 👉 👌 âœŒï¸ ðŸ‘Š ✊ ✋ 💪 👠🙌 👠🙠🖠🖕 🖖
Nature
Back to top
Trees, Plants and Flower
🌱 🌲 🌳 🌴 🌵 🌷 🌸 🌹 🌺 🌻 🌼 💠🌾 🌿 🀠ðŸ 🂠🃠🄠🌰
Animal
🀠ðŸ ðŸ 🹠🂠🃠🄠🮠🅠🆠🯠🇠🰠🈠🱠🎠🴠ðŸ 👠ðŸ 📠🔠🤠🣠🥠🦠🧠😠🪠🫠🗠🖠🷠🽠🕠🩠🶠🺠🻠🨠🼠🵠🙈 🙉 🙊 💠🉠🲠🊠ðŸ 🢠🸠🋠🳠🬠🙠🟠ðŸ 🡠🚠🌠🛠🜠ðŸ 🞠ðŸ¾
Weather, Environment and Space
Back to top
âš¡ï¸ ðŸ”¥ 🌙 â˜€ï¸ â›…ï¸ â˜ï¸ 💧 💦 â˜”ï¸ ðŸ’¨ â„ï¸ ðŸŒŸ âï¸ ðŸŒ ðŸŒ„ 🌅 🌈 🌊 🌋 🌌 🗻 🗾 🌠🌠🌎 🌠🌑 🌒 🌓 🌔 🌕 🌖 🌗 🌘 🌚 🌠🌛 🌜 🌞
Food and Drink
🅠🆠🌽 ðŸ 🇠🈠🉠🊠🋠🌠ðŸ 🎠ðŸ ðŸ 👠💠📠🔠🕠🖠🗠😠🙠🚠🛠🜠ðŸ 🞠🟠🡠🢠🣠🤠🥠🦠🧠🨠🩠🪠🫠🬠ðŸ ðŸ® ðŸ¯ ðŸ° ðŸ± ðŸ² ðŸ³ ðŸ´ ðŸµ â˜•ï¸ ðŸ¶ ðŸ· ðŸ¸ ðŸ¹ ðŸº ðŸ» ðŸ¼
Celebration
Back to top
Birthdays, Holidays and Occassion
🎀 🎠🎂 🎃 🎄 🎋 🎠🎑 🎆 🎇 🎉 🎊 🎈 💫 ✨ 💥 🎓 👑 🎎 🎠🎠🎌 🮠ðŸ’
Heart
â¤ï¸ 💔 💌 💕 💞 💓 💗 💖 💘 💠💟 💜 💛 💚 💙
Activity
Back to top
Sport
🃠🚶 💃 🚣 🊠🄠🛀 🂠🎿 â›„ï¸ ðŸš´ 🚵 ðŸ‡ â›ºï¸ ðŸŽ£ âš½ï¸ ðŸ€ ðŸˆ âš¾ï¸ ðŸŽ¾ ðŸ‰ â›³ï¸ ðŸ† ðŸŽ½ ðŸ
Music and Performing Arts
🎹 🎸 🎻 🎷 🎺 🎵 🎶 🎼 🎧 🎤 🎠🎫 🎩 🎪 🎬 🎨
Games and Recreation
🎯 🎱 🎳 🎰 🎲 🎮 🎴 ðŸƒ ðŸ€„ï¸ ðŸŽ ðŸŽ¡ 🎢
Travel and Places
Back to top
Trains, Cars, Travel and Transport
🚃 🚞 🚂 🚋 🚠🚄 🚅 🚆 🚇 🚈 🚉 🚊 🚌 🚠🚎 🚠🚑 🚒 🚓 🚔 🚨 🚕 🚖 🚗 🚘 🚙 🚚 🚛 🚜 🚲 ðŸš â›½ï¸ ðŸš§ 🚦 🚥 🚀 ðŸš âœˆï¸ ðŸ’º âš“ï¸ ðŸš¢ 🚤 â›µï¸ ðŸš¡ 🚠🚟 🛂 🛃 🛄 🛅 💴 💶 💷 💵
Landmarks and Buildings
🗽 🗿 🌠🗼 â›²ï¸ ðŸ° ðŸ¯ ðŸŒ‡ 🌆 🌃 🌉 ðŸ 🡠🢠🬠ðŸ 🣠🤠🥠🦠🨠🩠💒 â›ªï¸ ðŸª ðŸ«
Flags
More emoji flags at emojiflags.com
🇦🇺 🇦🇹 🇧🇪 🇧🇷 🇨🇦 🇨🇱 🇨🇳 🇨🇴 🇩🇰 🇫🇮 🇫🇷 🇩🇪 ðŸ‡ðŸ‡° 🇮🇳 🇮🇩 🇮🇪 🇮🇱 🇮🇹 🇯🇵 🇰🇷 🇲🇴 🇲🇾 🇲🇽 🇳🇱 🇳🇿 🇳🇴 🇵🇠🇵🇱 🇵🇹 🇵🇷 🇷🇺 🇸🇦 🇸🇬 🇿🇦 🇪🇸 🇸🇪 🇨🇠🇹🇷 🇬🇧 🇺🇸 🇦🇪 🇻🇳
Objects & Symbols
Back to top
Technology
âŒšï¸ ðŸ“± 📲 💻 â° â³ âŒ›ï¸ ðŸ“· 📹 🎥 📺 📻 📟 📞 â˜Žï¸ ðŸ“ ðŸ’½ 💾 💿 📀 📼 🔋 🔌 💡 🔦 📡 💳 💸 💰 💎
Clothing and Fashion
🌂 👠👛 👜 💼 🎒 💄 👓 👒 👡 👠👢 👞 👟 👙 👗 👘 👚 👕 👔 👖
Tools, Envelopes and Stationery
🚪 🚿 🛠🚽 💈 💉 💊 🔬 🔠🔮 🔧 🔪 🔩 🔨 💣 🚬 🔫 🔖 📰 🔑 âœ‰ï¸ ðŸ“© 📨 📧 📥 📤 📦 📯 📮 📪 📫 📬 📠📄 📃 📑 📈 📉 📊 📅 📆 🔅 🔆 📜 📋 📖 📓 📔 📒 📕 📗 📘 📙 📚 📇 🔗 📎 📌 âœ‚ï¸ ðŸ“ ðŸ“ ðŸ“ ðŸš© 📠📂 âœ’ï¸ âœï¸ 📠🔠🔠🔒 🔓 📣 📢 🔈 🔉 🔊 🔇 💤 🔔 🔕 💠💬 🚸 🔠🔎
Signs, Chinese Characters and Letter
Back to top
🚫 â›”ï¸ ðŸ“› 🚷 🚯 🚳 🚱 📵 🔞 🉑 🉠💮 ãŠ™ï¸ ãŠ—ï¸ ðŸˆ´ 🈵 🈲 🈶 ðŸˆšï¸ ðŸˆ¸ 🈺 🈷 🈹 🈳 🈂 ðŸˆ ðŸˆ¯ï¸ ðŸ’¹ â‡ï¸ âœ³ï¸ âŽ âœ… âœ´ï¸ ðŸ“³ 📴 🆚 🅰 🅱 🆎 🆑 🅾 🆘 🆔 ðŸ…¿ï¸ ðŸš¾ 🆒 🆓 🆕 🆖 🆗 🆙 ðŸ§
Astrological Zodiac Signs
â™ˆï¸ â™‰ï¸ â™Šï¸ â™‹ï¸ â™Œï¸ â™ï¸ â™Žï¸ â™ï¸ â™ï¸ â™‘ï¸ â™’ï¸ â™“ï¸
Arrows, Numbers and Misc Symbol
Back to top
🚻 🚹 🚺 🚼 â™¿ï¸ ðŸš° 🚠🚮 â–¶ï¸ â—€ï¸ ðŸ”¼ 🔽 â© âª â« â¬ âž¡ï¸ â¬…ï¸ â¬†ï¸ â¬‡ï¸ â†—ï¸ â†˜ï¸ â†™ï¸ â†–ï¸ â†•ï¸ â†”ï¸ ðŸ”„ â†ªï¸ â†©ï¸ â¤´ï¸ â¤µï¸ ðŸ”€ 🔠🔂 #ï¸âƒ£ 0ï¸âƒ£ 1ï¸âƒ£ 2ï¸âƒ£ 3ï¸âƒ£ 4ï¸âƒ£ 5ï¸âƒ£ 6ï¸âƒ£ 7ï¸âƒ£ 8ï¸âƒ£ 9ï¸âƒ£ 🔟 🔢 🔤 🔡 ðŸ” â„¹ï¸ ðŸ“¶ 🎦 🔣 âž• âž– 〰 âž— âœ–ï¸ âœ”ï¸ ðŸ”ƒ â„¢ © ® 💱 💲 âž° âž¿ ã€½ï¸ â—ï¸ â“ â• â” â€¼ï¸ â‰ï¸ ⌠â•ï¸ 💯 🔚 🔙 🔛 🔠🔜 🌀 â“‚ï¸ â›Ž 🔯 🔰 🔱 âš ï¸ â™¨ï¸ â™»ï¸ ðŸ’¢ ðŸ’ â™ ï¸ â™£ï¸ â™¥ï¸ â™¦ï¸ â˜‘ï¸ âšªï¸ âš«ï¸ ðŸ”˜ 🔴 🔵 🔺 🔻 🔸 🔹 🔶 🔷 â–ªï¸ â–«ï¸ â¬›ï¸ â¬œï¸ â—¼ï¸ â—»ï¸ â—¾ï¸ â—½ï¸ ðŸ”² 🔳
Clock
🕠🕑 🕒 🕓 🕔 🕕 🕖 🕗 🕘 🕙 🕚 🕛 🕜 🕠🕞 🕟 🕠🕡 🕢 🕣 🕤 🕥 🕦 🕧
Skin Color
Back to top
Pale
👦🻠👧🻠👨🻠👩🻠👮🻠👰🻠👱🻠👲🻠👳🻠👴🻠👵🻠👶🻠👷🻠👸🻠💂🻠👼🻠🎅🻠🙇🻠ðŸ’🻠🙅🻠🙆🻠🙋🻠🙎🻠ðŸ™ðŸ» 💆🻠💇🻠💅🻠👂🻠👃🻠👋🻠ðŸ‘🻠👎🻠â˜ðŸ» 👆🻠👇🻠👈🻠👉🻠👌🻠✌🻠👊🻠✊🻠✋🻠💪🻠ðŸ‘🻠🙌🻠ðŸ‘🻠ðŸ™ðŸ» ðŸ–🻠🖕🻠🖖ðŸ»
Cream White
👦🼠👧🼠👨🼠👩🼠👮🼠👰🼠👱🼠👲🼠👳🼠👴🼠👵🼠👶🼠👷🼠👸🼠💂🼠👼🼠🎅🼠🙇🼠ðŸ’🼠🙅🼠🙆🼠🙋🼠🙎🼠ðŸ™ðŸ¼ 💆🼠💇🼠💅🼠👂🼠👃🼠👋🼠ðŸ‘🼠👎🼠â˜ðŸ¼ 👆🼠👇🼠👈🼠👉🼠👌🼠✌🼠👊🼠✊🼠✋🼠💪🼠ðŸ‘🼠🙌🼠ðŸ‘🼠ðŸ™ðŸ¼ ðŸ–🼠🖕🼠🖖ðŸ¼
Moderate Brown
👦🽠👧🽠👨🽠👩🽠👮🽠👰🽠👱🽠👲🽠👳🽠👴🽠👵🽠👶🽠👷🽠👸🽠💂🽠👼🽠🎅🽠🙇🽠ðŸ’🽠🙅🽠🙆🽠🙋🽠🙎🽠ðŸ™ðŸ½ 💆🽠💇🽠💅🽠👂🽠👃🽠👋🽠ðŸ‘🽠👎🽠â˜ðŸ½ 👆🽠👇🽠👈🽠👉🽠👌🽠✌🽠👊🽠✊🽠✋🽠💪🽠ðŸ‘🽠🙌🽠ðŸ‘🽠ðŸ™ðŸ½ ðŸ–🽠🖕🽠🖖ðŸ½
Dark Brown Emojis
👦🾠👧🾠👨🾠👩🾠👮🾠👰🾠👱🾠👲🾠👳🾠👴🾠👵🾠👶🾠👷🾠👸🾠💂🾠👼🾠🎅🾠🙇🾠ðŸ’🾠🙅🾠🙆🾠🙋🾠🙎🾠ðŸ™ðŸ¾ 💆🾠💇🾠💅🾠👂🾠👃🾠👋🾠ðŸ‘🾠👎🾠â˜ðŸ¾ 👆🾠👇🾠👈🾠👉🾠👌🾠✌🾠👊🾠✊🾠✋🾠💪🾠ðŸ‘🾠🙌🾠ðŸ‘🾠ðŸ™ðŸ¾ ðŸ–🾠🖕🾠🖖ðŸ¾
Black Emojis
👦🿠👧🿠👨🿠👩🿠👮🿠👰🿠👱🿠👲🿠👳🿠👴🿠👵🿠👶🿠👷🿠👸🿠💂🿠👼🿠🎅🿠🙇🿠ðŸ’🿠🙅🿠🙆🿠🙋🿠🙎🿠ðŸ™ðŸ¿ 💆🿠💇🿠💅🿠👂🿠👃🿠👋🿠ðŸ‘🿠👎🿠â˜ðŸ¿ 👆🿠👇🿠👈🿠👉🿠👌🿠✌🿠👊🿠✊🿠✋🿠💪🿠ðŸ‘🿠🙌🿠ðŸ‘🿠ðŸ™ðŸ¿ ðŸ–🿠🖕🿠🖖ðŸ¿
Extra
download font at the bottom (if you see rectangles)
Back to top
🌡 🌢 🌣 🌤 🌥 🌦 🌧 🌨 🌩 🌪 🌫 🌬 🌶 🽠🎔 🎕 🎖 🎗 🎘 🎙 🎚 🎛 🎜 🎠🎞 🎟 🅠🋠🌠ðŸ 🎠🔠🕠🖠🗠😠🙠🚠🛠🜠ðŸ 🞠🟠🱠🲠🳠🴠🵠🶠🷠🿠👠📸 📽 📾 🔾 🔿 🕄 🕅 🕆 🕇 🕈 🕉 🕊 🕨 🕩 🕪 🕫 🕬 🕠🕮 🕯 🕰 🕱 🕲 🕳 🕴 🕵 🕶 🕷 🕸 🕹 🕻 🕼 🕽 🕾 🕿 🖀 🖠🖂 🖃 🖄 🖅 🖆 🖇 🖈 🖉 🖊 🖋 🖌 🖠🖎 🖠🖑 🖒 🖓 🖔 🖗 🖘 🖙 🖚 🖛 🖜 🖠🖞 🖟 🖠🖡 🖢 🖣 🖥 🖦 🖧 🖨 🖩 🖪 🖫 🖬 🖠🖮 🖯 🖰 🖱 🖲 🖳 🖴 🖵 🖶 🖷 🖸 🖹 🖺 🖻 🖼 🖽 🖾 🖿 🗀 🗀 🗂 🗃 🗄 🗅 🗆 🗇 🗈 🗉 🗊 🗋 🗌 🗠🗎 🗠🗠🗑 🗒 🗓 🗔 🗕 🗖 🗗 🗘 🗙 🗚 🗛 🗜 🗠🗞 🗟 🗠🗡 🗢 🗣 🗤 🗥 🗦 🗧 🗨 🗩 🗪 🗫 🗬 🗠🗯 🗯 🗰 🗱 🗲 🗳 🗴 🗵 🗶 🗷 🗸 🗹 🗺 🛆 🛇 🛈 🛉 🛊 🛋 🛌 🛠🛎 🛠🛠🛡 🛢 🛣 🛤 🛥 🛦 🛧 🛨 🛩 🛪 🛫 🛬 🛰 🛱 🛲 🛳
Extra 2
Back to top
☠☺ ☹ ✊ ✋ ☠✌ âš¡ ✨ ╠⌠â ╠┠◠ⓠ℠☀ â›… ☔ ⛄ ☎ âž¿ ✂ âš½ âš¾ ⛳ ♠♥ ♣ ♦ ☕ ♤ ♡ ♢ ♧ ⰠⳠ⌛ ⌚ ♨ ✠✒ ✉ âš“ ⛪ ⛺ ⛲ ⛵ ✈ ⛽ âš â›”  ⬆ ⬇ ⬅ âž¡ ↗ ↖ ↘ ↙ â—€ â–¶ ⪠⩠♿ ㊙ ㊗ ✳ ✴ ♈ ♉ ♊ ♋ ♌ ♠♎ ♠♠♑ â™’ ♓ ⛎ ╠⌠© ® â„¢ ⫠⬠↕ ↔ ↩ ↪ ⤴ ⤵ ℹ ⎠Ⓜ âš« ⚪ â—¼ â—» â–ª â–« ✖ âž• âž– âž— âž° 〰 â™» ☢ ☣ ☠☤ âš• âšš †☯ âš– ☮ ⚘ âš” ☠⚒ âš› âšœ ☥ ✠✙ ✞ ✟ ✧ ⋆ ★ ☆ ✪ ✫ ✬ ✠✮ ✯ ✰ ✡ ☫ ☬ ☸ ✵ ₠⚘ †⃠â ✼ ♫ ♪ ☃ â… â† â˜‚ ⦠♕ â™› â™” â™– ♜ ☾ → ⇒ ⟹ ⇨ ⇰ âž© ➪ âž« ➬ âž âž® ➯ âž² âž³ âžµ ➸ âž» ➺ âž¼ âž½ ☜ ☟ âž¹ âž· ↶ ↷ ✆ ⌘ ⎋ ⎠â ⎈ ⎌ ⟠⥠ツ ღ ☻
Leave your own comment
Comments have been disabled
# December 17, 2009 - 10:16 pm PST